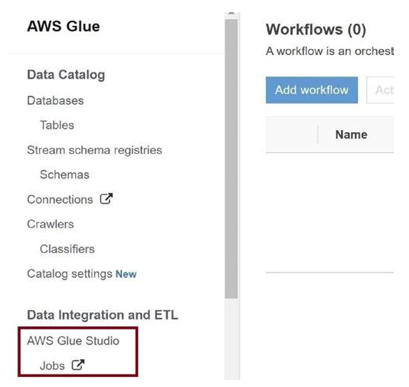
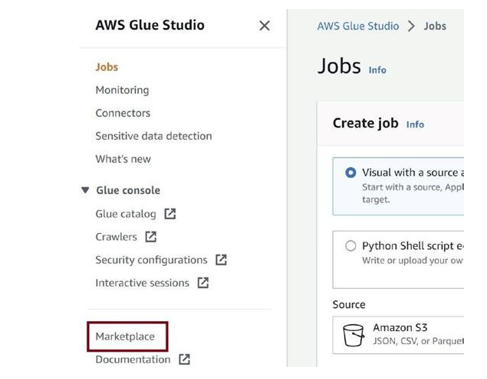
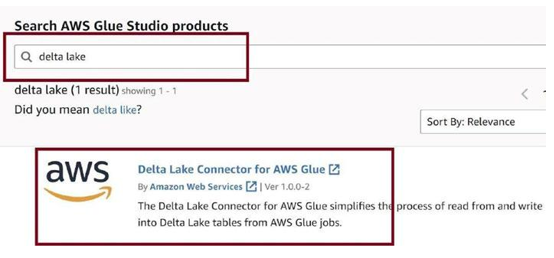
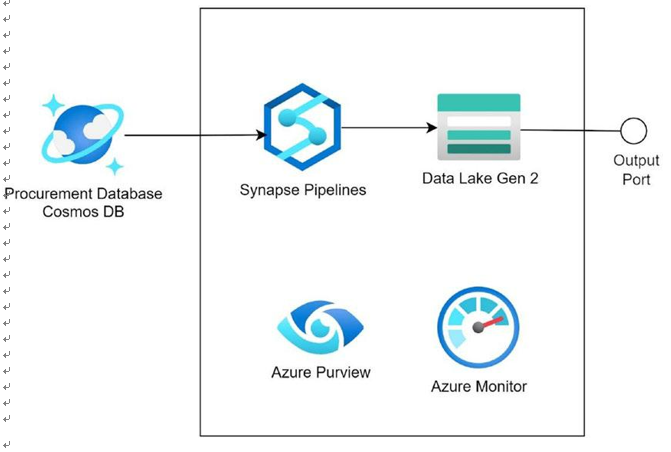
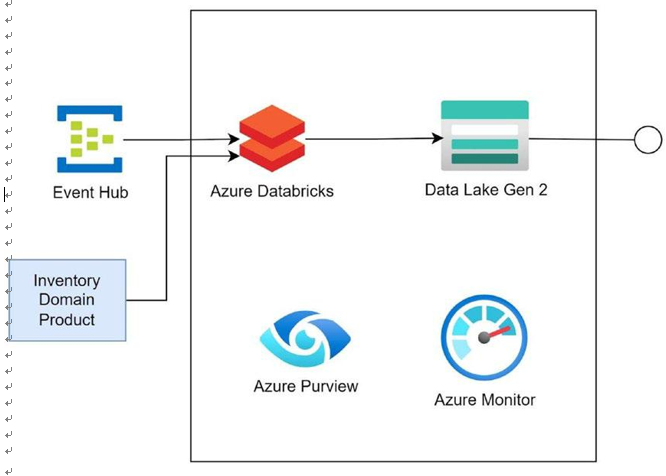
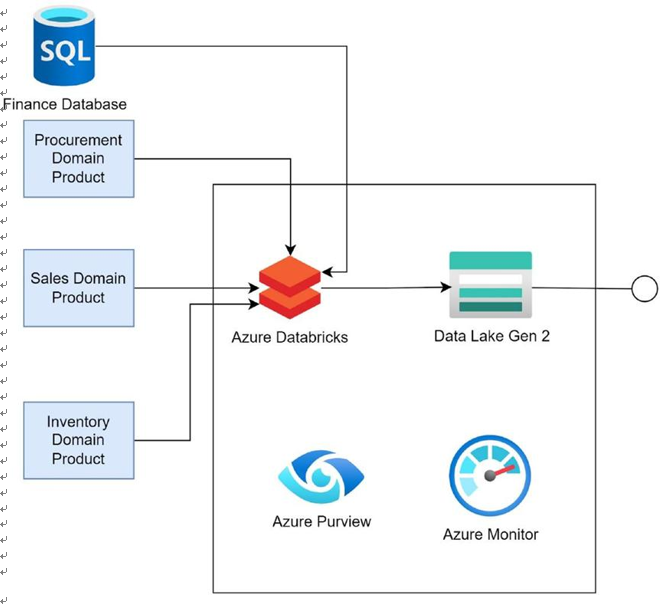
Real-time Processing in Detail
Real-time processing is a crucial aspect of the data processing workflow, focusing on immediate data processing and delivery. The process begins with data collection, where data is gathered from various sources in real-time. Once collected, the data undergoes a
data cleaning phase to eliminate errors and inconsistencies, ensuring its accuracy and reliability. The next step is data transformation, where the data is converted into a format that is suitable for real-time analysis, enabling prompt insights and actions.
After transformation, the data enters the data processing phase, where it is processed in real-time. This means that the data is acted upon immediately upon receipt, allowing for timely responses and decision-making. Finally, the processed data is delivered to the intended users or stakeholders in real-time, enabling them to take immediate action based on the insights derived from the data.
Real-time processing offers several benefits. It allows for data to be processed as soon as it is received, ensuring up-to-date and actionable information. It is particularly useful for data that requires immediate attention or action. Real-time processing also caters to data that is time sensitive, ensuring that it is analyzed and acted upon in a timely manner.
However, there are challenges associated with real-time processing. It can be expensive to implement and maintain the infrastructure and systems required for real-time processing. Scaling real-time processing to handle large volumes of data can also be challenging, as it requires robust and efficient resources. Additionally, ensuring the availability and reliability of real-time processing systems can be complex, as any downtime or interruptions can impact the timely processing and delivery of data.
In summary, real-time processing plays a vital role in the data processing workflow, emphasizing immediate data processing and delivery. Its benefits include prompt analysis and action based on up-to-date data, which is particularly useful for time-sensitive or critical information. Nevertheless, challenges such as cost, scalability, and system availability need to be addressed to ensure the effective implementation of real-time processing.
Example of Real-time Data Processing with Apache Kafka:
Consider a ride-sharing service that needs to track the real-time location of its drivers to optimize routing and improve customer service. In this scenario, a real-time data processing pipeline is employed. The pipeline continuously ingests and processes the driver location updates as they become available.
The ride-sharing service utilizes a messaging system, such as Apache Kafka, to receive real-time location events from drivers’ mobile devices. The events are immediately processed by the pipeline as they arrive. The processing component of the pipeline may include filtering, enrichment, and aggregation operations.
For example, the pipeline can filter out events that are not relevant for analysis, enrich the events with additional information such as driver ratings or past trip history, and aggregate the data to calculate metrics like average driver speed or estimated time of arrival (ETA).
The processed real-time data can then be used to power various applications and services. For instance, the ride-sharing service can use this data to dynamically update driver positions on the customer-facing mobile app, optimize route calculations in real- time, or generate alerts if a driver deviates from the expected route.
Real-time data processing pipelines provide organizations with the ability to respond quickly to changing data, enabling immediate action and providing real-time insights that are essential for time-sensitive applications and services.
One of the ways to implement real-time processing is to design a data pipeline using tools like Apache Kafka, which involves several steps.
Here’s a high-level overview of the process:
• Identify Data Sources: Determine the data sources you want to collect and analyze. These could be databases, logs, IOT devices, or any other system generating data.
• Define Data Requirements: Determine what data you need to collect and analyze from the identified sources. Define the data schema, formats, and any transformations required.
• Install and Configure Apache Kafka: Set up an Apache Kafka cluster to act as the backbone of your data pipeline. Install and configure Kafka brokers, Zookeeper ensemble (if required), and other necessary components.
• Create Kafka Topics: Define Kafka topics that represent different data streams or categories. Each topic can store related data that will be consumed by specific consumers or analytics applications.
• Data Ingestion: Develop data producers that will publish data to the Kafka topics. Depending on the data sources, you may need to build connectors or adapters to fetch data and publish it to Kafka.
• Data Transformation: If necessary, apply any required data transformations or enrichment before storing it in Kafka. For example, you may need to cleanse, aggregate, or enrich the data using tools like Apache Spark, Apache Flink, or Kafka Streams.
• Data Storage: Configure Kafka to persist data for a certain retention period or size limit. Ensure you have sufficient disk space and choose appropriate Kafka storage settings based on your data volume and retention requirements.
• Data Consumption: Develop data consumers that subscribe to the Kafka topics and process the incoming data. Consumers can perform various operations, such as real-time analytics, batch processing, or forwarding data to external systems.
• Data Analysis: Integrate analytics tools or frameworks like Apache Spark, Apache Flink, or Apache Storm to process and analyze the data consumed from Kafka. You can perform aggregations, complex queries, machine learning, or any other required analysis.
• Data Storage and Visualization: Depending on the output of your data analysis, you may need to store the results in a data store such as a database or a data warehouse. Additionally, visualize the analyzed data using tools like Apache Superset, Tableau, or custom dashboards.
• Monitoring and Management: Implement monitoring and alerting mechanisms to ensure the health and performance of your data pipeline. Monitor Kafka metrics, consumer lag, data throughput, and overall system performance. Utilize tools like Prometheus, Grafana, or custom monitoring solutions.
• Scaling and Performance: As your data volume and processing requirements grow, scale your Kafka cluster horizontally by adding more brokers, and fine-tune various Kafka configurations to optimize performance.
It’s important to note that designing a data pipeline using Apache Kafka is a complex task, and the specifics will depend on your specific use case and requirements. It’s recommended to consult the official Apache Kafka documentation and seek expert guidance when implementing a production-grade data pipeline.