Create an AWS Glue Job to Convert the Raw Data into a Delta Table
Go to AWS Glue and click on Go to workflows as shown in Figure 3-60. We will get navigated to the AWS Glue studio, where we can create the AWS Glue job to convert the raw CSV file into a delta table.
Figure 3-60. Go to workflows
Click on Jobs as in Figure 3-61. We need to create the workflow for the job and execute it to convert the raw CSV file into a delta table.
Figure 3-61. Click on Jobs
We will be using the delta lake connector in the AWS Glue job. We need to activate it.
Go to the Marketplace, as in Figure 3-62.
Figure 3-62. Click on Marketplace
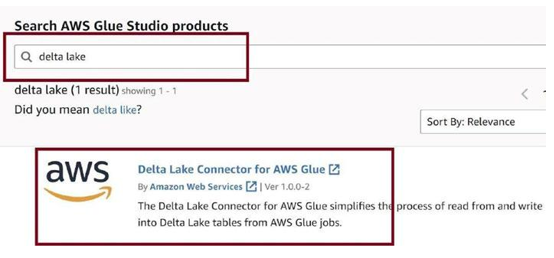
Search for delta lake as in Figure 3-63, and then click on Delta Lake Connector for AWS Glue.
Figure 3-63. Activate delta lake connector
Click on Continue to Subscribe as in Figure 3-64.
Figure 3-64. Continue to Subscribe
Click on Continue to Configuration as in Figure 3-65.
Figure 3-65. Continue to Configuration
Click on Continue to Launch as in Figure 3-66.
Figure 3-66. Continue to Launch
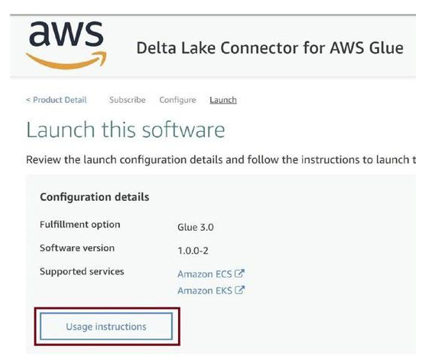
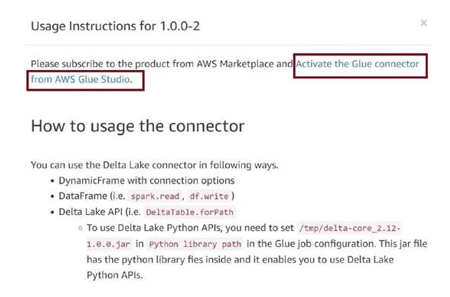
Click on Usage instructions as in Figure 3-67. The usage instructions will open up. We have some steps to perform on that page.
Figure 3-67. Click Usage Instructions
Read the usage instructions once and then click on Activate the Glue connector from AWS Glue Studio, as in Figure 3-68.
Figure 3-68. Activate Glue connector
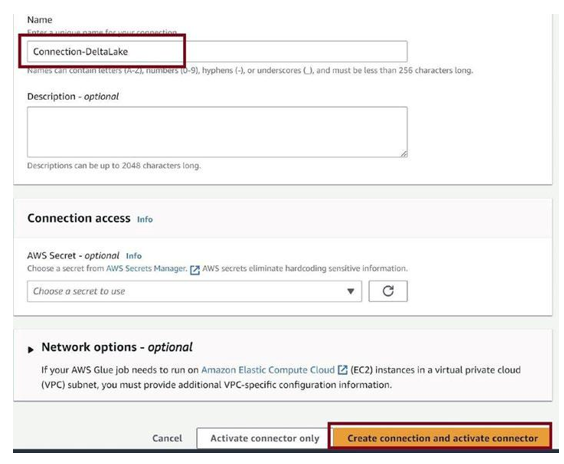
Provide a name for the connection, as in Figure 3-69, and then click on Create a connection and activate connector.
Figure 3-69. Create connection and activate connector
Once the connector gets activated, go back to the AWS Glue studio and click on Jobs, as in Figure 3-70.
Figure 3-70. Click on Jobs
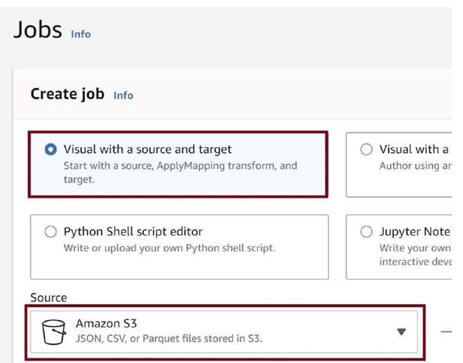
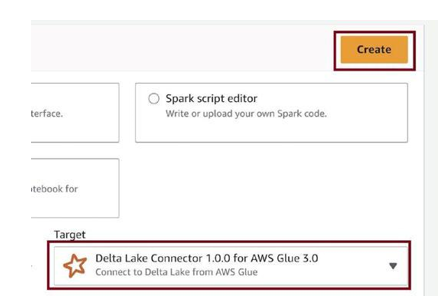
Select option Visual with a source and target and depict the source as Amazon S3, as in Figure 3-71.
Figure 3-71. Configure source
Select the target as Delta Lake Connector 1.0.0 for AWS Glue 3.0, as in Figure 3-72. We activated the connector in the marketplace and created a connection earlier. Click on Create.
Figure 3-72. Configure target
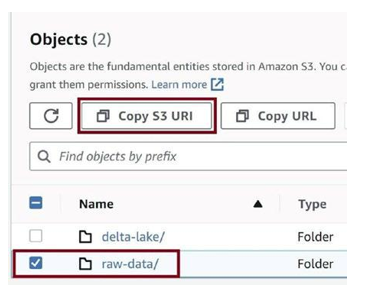
Go to the S3 bucket and copy the S3 URI for the raw-data folder, as in Figure 3-73.
Figure 3-73. Copy URI
Provide the S3 URI you copied and configure the data source, as in Figure 3-74. Make sure you mark the data format as CSV and check Recursive.
Figure 3-74. Source settings
Scroll down and check the First line of the source file contains column headers option, as in Figure 3-75.
Figure 3-75. Source settings
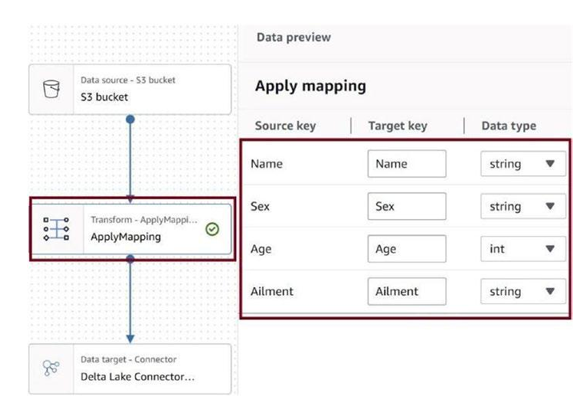
Click on ApplyMapping as in Figure 3-76 and provide the data mappings and correct data types. The target parquet file will be generated with these data types.
Figure 3-76. Configure mappings
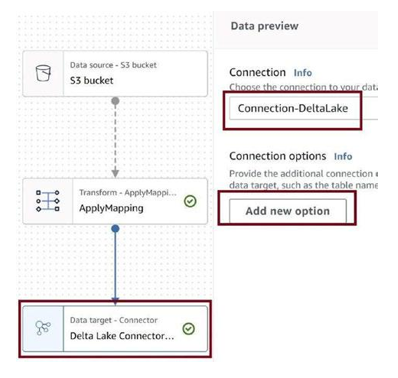
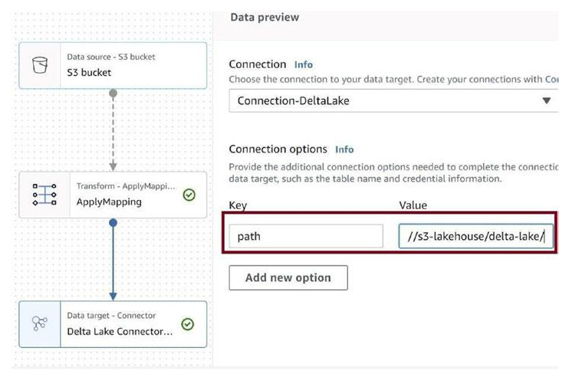
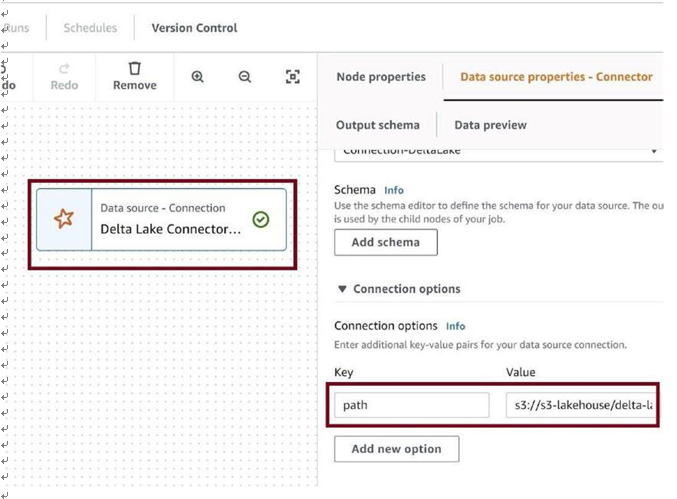
Click on Delta Lake Connector, and then click on Add new option, as in Figure 3-77.
Figure 3-77. Add new option
Provide Key as path and Value as URI for the delta-lake folder in the S3 bucket, as in Figure 3-78.
Figure 3-78. Configure target
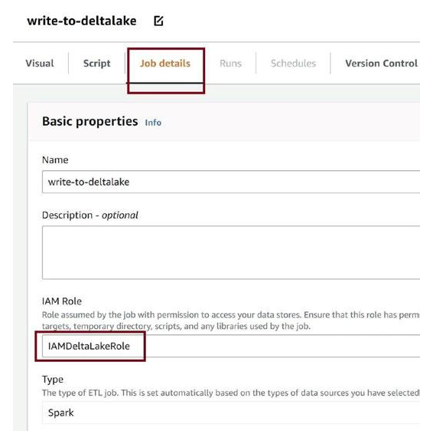
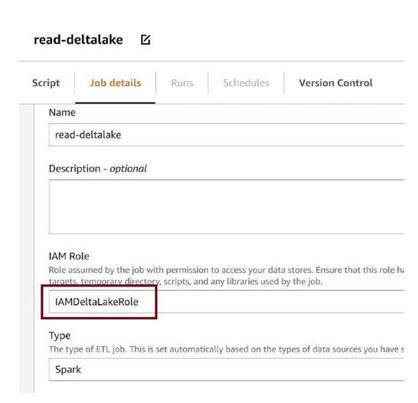
Go to the Job details as in Figure 3-79 and set IAM Role as the role we created as a prerequisite with all necessary permissions.
Figure 3-79. Provide IAM role
Click on Save as in Figure 3-80 and then run the job.
Figure 3-80. Save and run
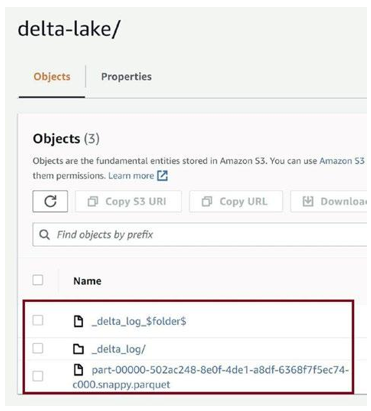
Once the job runs successfully, go to the delta-lake folder in the S3 bucket. You can see the delta table parquet file generated in Figure 3-81.
Figure 3-81. Generated delta table in the delta-lake folder
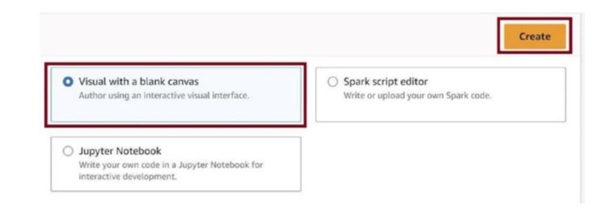
Let us query the delta table using the AWS Glue job. Go to the job in AWS Glue studio, select Visual with a blank canvas, and then click on Create, as in Figure 3-82.
Figure 3-82. Create new job
Add Delta Lake Connector, then provide the Key as path and Value as URI for the parquet file in the delta-lake folder in the S3 bucket, as in Figure 3-83.
Figure 3-83. Configure delta lake connector
Set the IAM Role to the role in the prerequisites that has all necessary permissions, as in Figure 3-84.
Figure 3-84. Provide IAM role
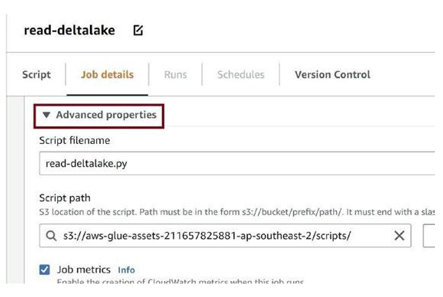
Expand Advanced properties, as in Figure 3-85.
Figure 3-85. Expand Advanced properties section
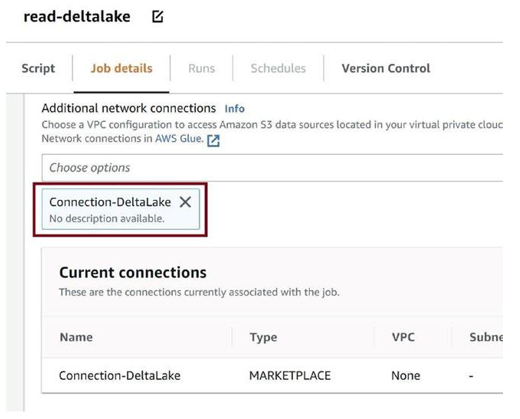
Scroll down and provide the connection we created for the delta lake connector, as in Figure 3-86. Save the job and run it.
Figure 3-86. Provode connection
Once the job executes successfully, you can see the table data in the logs for the job, as in Figure 3-87.
There are two major types of data pipeline widely in use: batch and real-time data processing.
Batch processing is when data is collected over a period and processed all at once. This is typically done for large amounts of data that do not need to be processed in real-time. For example, a company might batch process their sales data once a month to generate reports.
Real-time processing is when data is processed as soon as it is received. This is typically done for data that needs to be acted on immediately, such as financial data or sensor data. For example, a company might use real-time processing to monitor their stock prices or to detect fraud.
The type of data processing that is used depends on the specific needs of the organization. For example, a company that needs to process large amounts of data might use batch processing, while a company that needs to process data in real-time might use real-time processing.
Figure 5-5. A generic batch and stream-based data processing in a modern data warehouse
Batch Processing in Detail
Batch processing is a key component of the data processing workflow, involving a series of stages from data collection to data delivery (Figure 5-5). The process begins with data collection, where data is gathered from various sources. Once collected, the data undergoes a data cleaning phase to eliminate errors and inconsistencies, ensuring its reliability for further analysis. The next step is data transformation, where the data is formatted and structured in a way that is suitable for analysis, making it easier to extract meaningful insights.
After transformation, the data is stored in a centralized location, such as a database or data warehouse, facilitating easy access and retrieval. Subsequently, data analysis techniques are applied to extract valuable insights and patterns from the data,
supporting decision-making and informing business strategies. Finally, the processed data is delivered to the intended users or stakeholders, usually in the form of reports, dashboards, or visualizations.
One of the notable advantages of batch processing is its ability to handle large amounts of data efficiently. By processing data in batches rather than in real-time, it enables better resource management and scalability. Batch processing is particularly beneficial for data that doesn’t require immediate processing or is not time-sensitive, as it can be scheduled and executed at a convenient time.
However, there are also challenges associated with batch processing. Processing large volumes of data can be time-consuming, as the processing occurs in sets or batches. Additionally, dealing with unstructured or inconsistent data can pose difficulties during the transformation and analysis stages. Ensuring data consistency and quality becomes crucial in these scenarios.
In conclusion, batch processing plays a vital role in the data processing workflow, encompassing data collection, cleaning, transformation, storage, analysis, and delivery. Its benefits include the ability to process large amounts of data efficiently and handle non-time-sensitive data. Nonetheless, challenges such as processing time and handling unstructured or inconsistent data need to be addressed to ensure successful implementation.
Example of Batch Data Processing with Databricks
Consider a retail company that receives sales data from multiple stores daily. To analyze this data, the company employs a batch data processing pipeline. The pipeline is designed to ingest the sales data from each store at the end of the day. The data is collected as CSV files, which are uploaded to a centralized storage system. The batch data pipeline is scheduled to process the data every night.
The pipeline starts by extracting the CSV files from the storage system and transforming them into a unified format suitable for analysis. This may involve merging, cleaning, and aggregating the data to obtain metrics such as total sales, top-selling products, and customer demographics. Once the transformation is complete, the processed data is loaded into a data warehouse or analytics database.
Analytics tools, such as SQL queries or business intelligence (BI) platforms, can then be used to query the data warehouse and generate reports or dashboards. For example, the retail company can analyze sales trends, identify popular products, and gain insights into customer behavior. This batch data processing pipeline provides valuable business insights daily, enabling data-driven decision-making.
In this use case, we will explore a scenario where batch processing of data is performed using CSV and flat files. The data will be processed and analyzed using Databricks, a cloud-based analytics platform, and stored in Blob storage.
Requirements:
• CSV and flat files containing structured data • Databricks workspace and cluster provisioned • Blob storage account for data storage
Steps:
Data Preparation:
• Identify the CSV and flat files that contain the data to be processed.
• Ensure that the files are stored in a location accessible to Databricks.
Databricks Setup:
• Create a Databricks workspace and provision a cluster with appropriate configurations and resources.
• Configure the cluster to have access to Blob storage.
Data Ingestion:
• Using Databricks, establish a connection to the Blob storage account.
• Write code in Databricks to read the CSV and flat files from Blob storage into Databricks’ distributed file system (DBFS) or as Spark dataframes.
Data Transformation:
• Utilize the power of Spark and Databricks to perform necessary data transformations.
• Apply operations such as filtering, aggregations, joins, and any other required transformations to cleanse or prepare the data for analysis.
Data Analysis and Processing:
• Leverage Databricks’ powerful analytics capabilities to perform batch processing on the transformed data.
• Use Spark SQL, DataFrame APIs, or Databricks notebooks to run queries, aggregations, or custom data processing operations.
Results Storage:
• Define a storage location within Blob storage to store the processed data.
• Write the transformed and processed data back to Blob storage in a suitable format, such as Parquet or CSV.
Data Validation and Quality Assurance:
• Perform data quality checks and validation on the processed data to ensure its accuracy and integrity.
• Compare the processed results with expected outcomes or predefined metrics to validate the batch processing pipeline.
Monitoring and Maintenance:
• Implement monitoring and alerting mechanisms to track the health and performance of the batch processing pipeline.
• Continuously monitor job statuses, data processing times, and resource utilization to ensure efficient execution.
Scheduled Execution:
• Set up a scheduled job or workflow to trigger the batch processing pipeline at predefined intervals.
• Define the frequency and timing based on the data refresh rate and business requirements.
Real-time processing is a crucial aspect of the data processing workflow, focusing on immediate data processing and delivery. The process begins with data collection, where data is gathered from various sources in real-time. Once collected, the data undergoes a
data cleaning phase to eliminate errors and inconsistencies, ensuring its accuracy and reliability. The next step is data transformation, where the data is converted into a format that is suitable for real-time analysis, enabling prompt insights and actions.
After transformation, the data enters the data processing phase, where it is processed in real-time. This means that the data is acted upon immediately upon receipt, allowing for timely responses and decision-making. Finally, the processed data is delivered to the intended users or stakeholders in real-time, enabling them to take immediate action based on the insights derived from the data.
Real-time processing offers several benefits. It allows for data to be processed as soon as it is received, ensuring up-to-date and actionable information. It is particularly useful for data that requires immediate attention or action. Real-time processing also caters to data that is time sensitive, ensuring that it is analyzed and acted upon in a timely manner.
However, there are challenges associated with real-time processing. It can be expensive to implement and maintain the infrastructure and systems required for real-time processing. Scaling real-time processing to handle large volumes of data can also be challenging, as it requires robust and efficient resources. Additionally, ensuring the availability and reliability of real-time processing systems can be complex, as any downtime or interruptions can impact the timely processing and delivery of data.
In summary, real-time processing plays a vital role in the data processing workflow, emphasizing immediate data processing and delivery. Its benefits include prompt analysis and action based on up-to-date data, which is particularly useful for time-sensitive or critical information. Nevertheless, challenges such as cost, scalability, and system availability need to be addressed to ensure the effective implementation of real-time processing.
Example of Real-time Data Processing with Apache Kafka:
Consider a ride-sharing service that needs to track the real-time location of its drivers to optimize routing and improve customer service. In this scenario, a real-time data processing pipeline is employed. The pipeline continuously ingests and processes the driver location updates as they become available.
The ride-sharing service utilizes a messaging system, such as Apache Kafka, to receive real-time location events from drivers’ mobile devices. The events are immediately processed by the pipeline as they arrive. The processing component of the pipeline may include filtering, enrichment, and aggregation operations.
For example, the pipeline can filter out events that are not relevant for analysis, enrich the events with additional information such as driver ratings or past trip history, and aggregate the data to calculate metrics like average driver speed or estimated time of arrival (ETA).
The processed real-time data can then be used to power various applications and services. For instance, the ride-sharing service can use this data to dynamically update driver positions on the customer-facing mobile app, optimize route calculations in real- time, or generate alerts if a driver deviates from the expected route.
Real-time data processing pipelines provide organizations with the ability to respond quickly to changing data, enabling immediate action and providing real-time insights that are essential for time-sensitive applications and services.
One of the ways to implement real-time processing is to design a data pipeline using tools like Apache Kafka, which involves several steps.
Here’s a high-level overview of the process:
• Identify Data Sources: Determine the data sources you want to collect and analyze. These could be databases, logs, IOT devices, or any other system generating data.
• Define Data Requirements: Determine what data you need to collect and analyze from the identified sources. Define the data schema, formats, and any transformations required.
• Install and Configure Apache Kafka: Set up an Apache Kafka cluster to act as the backbone of your data pipeline. Install and configure Kafka brokers, Zookeeper ensemble (if required), and other necessary components.
• Create Kafka Topics: Define Kafka topics that represent different data streams or categories. Each topic can store related data that will be consumed by specific consumers or analytics applications.
• Data Ingestion: Develop data producers that will publish data to the Kafka topics. Depending on the data sources, you may need to build connectors or adapters to fetch data and publish it to Kafka.
• Data Transformation: If necessary, apply any required data transformations or enrichment before storing it in Kafka. For example, you may need to cleanse, aggregate, or enrich the data using tools like Apache Spark, Apache Flink, or Kafka Streams.
• Data Storage: Configure Kafka to persist data for a certain retention period or size limit. Ensure you have sufficient disk space and choose appropriate Kafka storage settings based on your data volume and retention requirements.
• Data Consumption: Develop data consumers that subscribe to the Kafka topics and process the incoming data. Consumers can perform various operations, such as real-time analytics, batch processing, or forwarding data to external systems.
• Data Analysis: Integrate analytics tools or frameworks like Apache Spark, Apache Flink, or Apache Storm to process and analyze the data consumed from Kafka. You can perform aggregations, complex queries, machine learning, or any other required analysis.
• Data Storage and Visualization: Depending on the output of your data analysis, you may need to store the results in a data store such as a database or a data warehouse. Additionally, visualize the analyzed data using tools like Apache Superset, Tableau, or custom dashboards.
• Monitoring and Management: Implement monitoring and alerting mechanisms to ensure the health and performance of your data pipeline. Monitor Kafka metrics, consumer lag, data throughput, and overall system performance. Utilize tools like Prometheus, Grafana, or custom monitoring solutions.
• Scaling and Performance: As your data volume and processing requirements grow, scale your Kafka cluster horizontally by adding more brokers, and fine-tune various Kafka configurations to optimize performance.
It’s important to note that designing a data pipeline using Apache Kafka is a complex task, and the specifics will depend on your specific use case and requirements. It’s recommended to consult the official Apache Kafka documentation and seek expert guidance when implementing a production-grade data pipeline.
Data pipelines find applications in various industries and domains, enabling organizations to address specific data processing needs and derive valuable insights. Let’s explore some common use cases where data pipelines play a pivotal role:
• E-commerce Analytics and Customer Insights: E-commerce businesses generate vast amounts of data, including customer interactions, website clicks, transactions, and inventory data. Data pipelines help collect, process, and analyze this data in real-time, providing valuable insights into customer behavior, preferences, and trends. These insights can be used for personalized marketing campaigns, targeted recommendations, inventory management, and fraud detection.
• Internet of Things (IOT) Data Processing: With the proliferation of IOT devices, organizations are collecting massive volumes of sensor data. Data pipelines are essential for handling and processing this continuous stream of data in real-time. They enable organizations to monitor and analyze IOT sensor data for predictive maintenance, anomaly detection, environmental monitoring, and optimizing operational efficiency.
• Financial Data Processing and Risk Analysis: Financial institutions deal with a vast amount of transactional and market data. Data pipelines streamline the processing and analysis of this data, enabling real-time monitoring of financial transactions, fraud detection, risk analysis, and compliance reporting. By leveraging data pipelines, financial organizations can make informed decisions, detect anomalies, and mitigate risks effectively.
• Health Care Data Management and Analysis: The health-care industry generates massive amounts of data, including patient records, medical imaging, sensor data, and clinical trial results. Data pipelines assist in collecting, integrating, and analyzing this data to support clinical research, patient monitoring, disease prediction, and population health management. Data pipelines can also enable interoperability among various health-care systems and facilitate secure data sharing.
• Social Media Sentiment Analysis and Recommendation Engines:
Social media platforms generate vast amounts of user-generated content, opinions, and sentiments. Data pipelines play a critical role in collecting, processing, and analyzing this data to derive insights into customer sentiment, brand reputation, and social trends. Organizations can leverage these insights for sentiment analysis, social media marketing, personalized recommendations, and social listening.
• Supply Chain Optimization: Data pipelines are instrumental in optimizing supply chain operations by integrating data from various sources, such as inventory systems, logistics providers, and sales data. By collecting, processing, and analyzing this data, organizations can gain real-time visibility into their supply chain, optimize inventory levels, predict demand patterns, and improve overall supply chain efficiency.
• Fraud Detection and Security Analytics: Data pipelines are widely used in fraud detection and security analytics applications across industries. By integrating and processing data from multiple sources, such as transaction logs, access logs, and user behavior data, organizations can detect anomalies, identify potential security threats, and take proactive measures to mitigate risks.
• Data Warehousing and Business Intelligence: Data pipelines play a crucial role in populating data warehouses and enabling business intelligence initiatives. They facilitate the extraction, transformation, and loading (ETL) of data from various operational systems into a centralized data warehouse. By ensuring the timely and accurate transfer of data, data pipelines enable organizations to perform in- depth analyses, generate reports, and make data-driven decisions.
These are just a few examples of how data pipelines are utilized across industries. The flexibility and scalability of data pipelines make them suitable for diverse data processing needs, allowing organizations to leverage their data assets to gain valuable insights and drive innovation.
In conclusion, data pipelines offer a wide range of benefits and advantages that empower organizations to efficiently manage and process their data. From improving data processing speed and scalability to enabling real-time analytics and advanced insights, data pipelines serve as a catalyst for data-driven decision-making and innovation. By embracing data pipelines, organizations can leverage the full potential of their data assets, derive meaningful insights, and stay ahead in today’s data-driven landscape.
Data Governance Empowered by Data Orchestration: Enhancing Control and Compliance
Data governance plays a crucial role in ensuring the quality, integrity, and security of data within an organization. Data orchestration, with its ability to centralize and manage data workflows, can greatly support data governance initiatives. By implementing data orchestration practices, organizations can enhance their data governance strategies in the following ways:
• Data Consistency: Data orchestration enables organizations to establish standardized data workflows, ensuring consistent data collection, integration, and transformation processes. This consistency helps maintain data quality and integrity throughout the data lifecycle.
• Data Lineage and Auditability: With data orchestration, organizations can track and document the movement and transformation of data across various systems and processes. This lineage provides transparency and traceability, enabling data governance teams to understand the origin and history of data, facilitating compliance requirements and data audits.
• Data Access Controls: Data orchestration tools can enforce access controls and data security measures, ensuring that only authorized individuals or systems have appropriate access to sensitive data. This helps protect data privacy and ensure compliance with regulatory frameworks, such as GDPR or HIPAA.
• Data Cataloging and Metadata Management: Data orchestration platforms often include features for data cataloging and metadata management. These capabilities allow organizations to create
a centralized repository of data assets, including metadata descriptions, data dictionaries, and data classifications. Such metadata management facilitates data governance efforts by providing comprehensive information about data sources, definitions, and usage.
• Data Quality Monitoring: Data orchestration tools can integrate with data quality monitoring solutions to continuously assess the quality and accuracy of data. By implementing data quality checks and validations at different stages of the orchestration process, organizations can proactively identify and address data quality issues, improving overall data governance practices.
• Data Retention and Archiving: Data orchestration can incorporate data retention policies and archiving mechanisms, ensuring compliance with legal and regulatory requirements for data retention. Organizations can define rules for data expiration, archival storage, and data disposal, thereby maintaining data governance standards for data lifecycle management.
In summary, data orchestration provides a foundation for effective data governance by enabling consistent workflows, ensuring data lineage and auditability, enforcing access controls, facilitating data cataloging and metadata management, monitoring data quality, and supporting data retention and archiving. By incorporating data orchestration practices into their data governance strategies, organizations can establish robust and compliant data management frameworks.
Now, let us use the data mesh principles we discussed and design a data mesh on Azure. We will take a use case of an enterprise consisting of finance, sales, human resources, procurement, and inventory departments. Let us build a data mesh that can expose data for each of these departments. The data generated by these departments are consumed across each of them. The item details in the inventory department are used in the sales department while generating an invoice when selling items to a prospective customer. Human resources payroll data and rewards and recognition data are used in the finance department to build the balance sheet for the department. The sales data from the sales department and the procurement data from the procurement department are used in the finance department when building the balance sheet for the company.
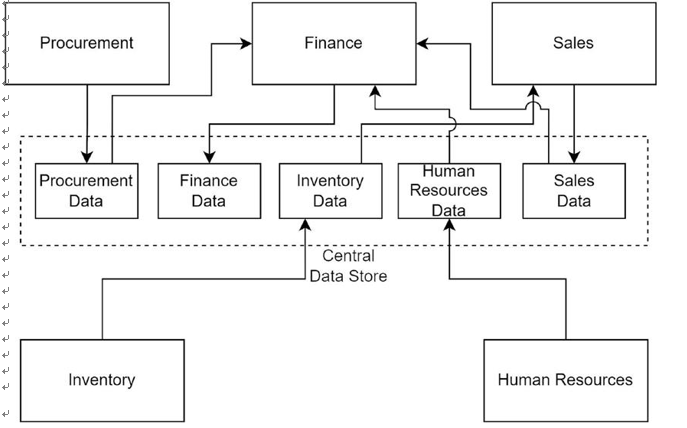
Figure 4-2. As-is data architecture
Figure 4-2 represents the as-is data architecture for the enterprise. The data are managed by a central data store. Each of the departments stores their data in the central data store. The finance department consumes data from human resources, sales, and procurement. Inventory data is consumed by the sales department. The central data team manages the data warehouse that stores and manages the central data. Each of these departments has a dependency on the central data team for data management, storage, and governance. The data engineers in the central data team are not experts for these domains. They do not understand how this data is produced or consumed. However, the engineers in the central data team are experts in storing and managing these data. The following are the steps to design a data mesh architecture on Azure:
Let us design data products for each of the domains.
Create Data Product for Human Resources Domain
We can start with the human resources domain product.
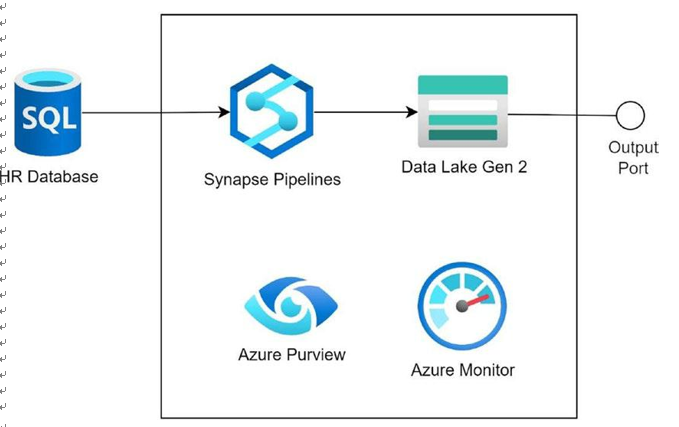
Figure 4-3. Human resources domain product
Figure 4-3 depicts the human resources domain product. The enterprise uses different human resources applications and portals that perform human resources tasks, like employee attendance, timecards, rewards and recognitions, performance management, and many more. All these human resources data are stored in the HR database built using Azure SQL. The Synapse pipeline reads the data from the HR database, transforms it into a consumable format, and then stores the data in the Synapse SQL pool. The Synapse pipeline can use the Copy activity to fetch the data from the HR database and put it in the Synapse SQL pool after processing the data. The Synapse SQL pool exposes the data to other domain products for consumption. Operational logs and metrics for Synapse are stored in Azure Monitor. Azure Monitor can be used to diagnose any run-time issues in the product. Azure Purview scans data capture and stores the data lineage, data schema, and other metadata information about the data that can help in discovering the data.
Create Data Product for Inventory Domain
Let us now design the inventory domain product.
Figure 4-4. Inventory resources domain product
Figure 4-4 depicts the inventory domain product. The enterprise uses different inventory applications and portals that manage the inventory of the products that the enterprise develops. These applications add products’ stock and information data, distribution details, and other necessary metadata information. All these inventory data are stored in the inventory database built using Azure SQL. The Synapse pipeline reads the data from the inventory database, transforms it into a consumable format, and then stores the data in an Azure Data Lake Gen2. The Synapse pipeline can use the Copy activity to fetch the data from the HR database and put it in the Azure Data Lake Gen2 after processing it. Azure Data Lake Gen2 exposes the data to other domain products for consumption. Operational logs and metrics for Synapse are stored in Azure Monitor. Azure Monitor can be used to diagnose the run-time issues in the product. Azure Purview scans data capture and stores the data lineage, data schema, and other metadata information about the data that can help in discovering the data.
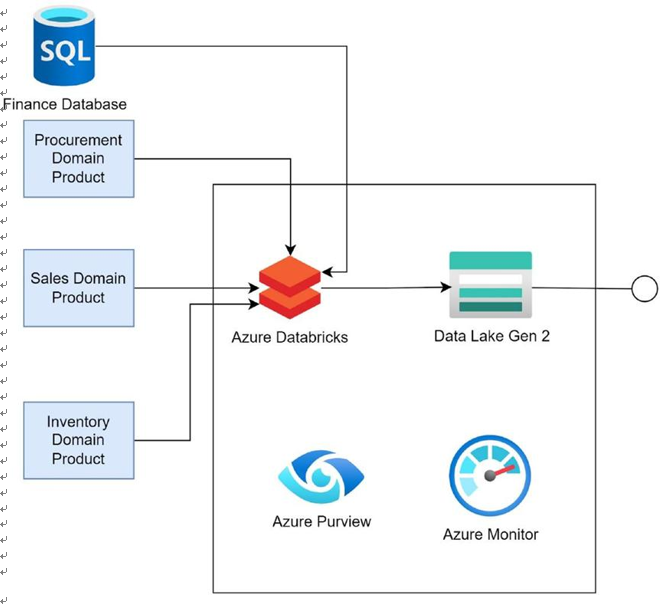
Figure 4-7 depicts the finance domain product, which consumes data from the inventory, sales, and procurement domain products. The volume of data is huge. Azure Databricks is used to manage the huge amounts of data being ingested. Spark pipelines transform the data and put it in an Azure Data Lake Gen2, which exposes the data to other domain products for consumption. Operational logs and metrics for Synapse are stored in Azure Monitor. Azure Monitor can be used to diagnose the run-time issues in the product. Azure Purview scans data capture and stores the data lineage, data schema, and other metadata information that can help in discovering the data.
Create Self-Serve Data Platform
The self-serve data platform consists of the following components, which give data producers and consumers a self-service experience:
• Data mesh experience plane
• Data product experience plane
• Infrastructure plane
Figure 4-8 depicts the Azure services that can be used to build the self-serve data platform.
Figure 4-8. Self-serve platform components
Data Mesh Experience Plane
The data mesh experience plane helps customers to discover the data products, explore metadata, see relationships among the data, and so on. The data mesh plane is used by the data governance team to ensure data compliance and best practices by giving them a way to audit and explore the data. Azure Purview can scan the data products and pull the data information from the products, like metadata, data schemas, data lineage, etc.
Data Product Experience Plane
The data product experience plane helps the data producers to add, modify, and delete data in the domain products. Azure Functions can be used in data products to allow data producers to add, modify, or delete the data in the domain product. The Purview catalog in the domain product will expose the data schema definitions and metadata, allowing the data producers to work with the data in the data domain.
Infrastructure Plane
The infrastructure plane helps in self-provisioning of the data domain infrastructure. You can use Azure Resource Manager APIs exposed through Azure Functions to create and destroy infrastructure for the data domain products.
Federated Governance
Azure Policies can be used to bring in federated governance. Data landing zones can be created using Azure Policies that can control and govern API access and activities for the data producers and consumers. Azure Functions and Azure Resource Manager APIs can also be used for governance purposes. Azure Monitor alerts can be used for generating governance alerts and notifications.
Data orchestration techniques are used to manage and coordinate the flow of data across various systems, applications, and processes within an organization. These techniques help ensure that data is collected, transformed, integrated, and delivered to the right place at the right time (Figure 5-1).
Figure 5-1. Some of the data engineering activities where orchestration is required
Data orchestration often involves data integration and extract, transform, load (ETL) processes. Data integration refers to combining data from different sources into a unified view, while ETL involves extracting data from source systems, transforming it to meet the target system’s requirements, and loading it into the destination system.
Orchestration has evolved alongside advancements in data management technologies and the increasing complexity of data ecosystems. Traditional approaches involved manual and ad-hoc methods of data integration, which were time-consuming and error-prone. As organizations started adopting distributed systems, cloud computing, and Big Data technologies, the need for automated and scalable data orchestration techniques became evident.
In the early days, batch processing was a common data orchestration technique. Data was collected over a period, stored in files or databases, and processed periodically. Batch processing is suitable for scenarios where real-time data processing is not necessary, and it is still used in various applications today.
With the rise of distributed systems and the need for real-time data processing, message-oriented middleware (MOM) became popular. MOM systems enable asynchronous communication between different components or applications by sending messages through a middleware layer. This technique decouples the sender and the receiver, allowing for more flexible and scalable data orchestration.
Enterprise Service Bus (ESB) is a software architecture that provides a centralized infrastructure for integrating various applications and services within an enterprise. It facilitates the exchange of data between different systems using standardized interfaces, protocols, and message formats. ESBs offer features like message routing, transformation, and monitoring, making them useful for data orchestration in complex environments.
Modern data orchestration techniques often involve the use of data pipelines and workflow orchestration tools both on cloud and on-premises for batch processing and real-time systems involving event-driven and continuous data streaming. The major areas that it covers are as follows:
• Data Pipelines and Workflow Orchestration: Modern data orchestration techniques often involve the use of data pipelines and workflow orchestration tools. Data pipelines provide a structured way to define and execute a series of data processing steps, including data ingestion, transformation, and delivery. Workflow orchestration tools help coordinate and manage the execution of complex workflows involving multiple tasks, dependencies, and error handling.
• Stream Processing and Event-Driven Architecture: As the demand for real-time data processing and analytics increased, stream processing and event-driven architecture gained prominence. Stream processing involves continuously processing and analyzing data streams in real-time, enabling organizations to derive insights and take immediate action. Event-driven architectures leverage events and event-driven messaging to trigger actions and propagate data changes across systems.
• Cloud-Based Data Orchestration: Cloud computing has greatly influenced data orchestration techniques. Cloud platforms offer various services and tools for data ingestion, storage, processing, and integration. They provide scalable infrastructure, on-demand resources, and managed services, making it easier to implement and scale data orchestration workflows.