Each of the domains exposing the data as products needs an infrastructure to host and operate the data. If we take a traditional approach, each of these domains will own their own infrastructure and have their own set of tooling and utilities to handle the data.
This phenomenon is not cost effective and requires a lot of effort from the infrastructure engineers in the domains. This approach also leads to duplicity of efforts across the domain teams.
A better approach would be to build a self-serve platform to facilitate the domains’ storing and exposing data as products. The platform will provide the necessary infrastructure to store and manage the data. The underlying infrastructure will be abstracted to the domain teams. It should expose necessary tooling that will enable the domain teams to manage their data and expose it as their domain’s product to other domain teams. The self-serve platform should clearly define with whom the data should be shared. It should provide an interface to the domain teams so they can manage their data products by using either declarative code or some other convenient manner.
Federated Computational Governance
Data are exposed as products in a data mesh and are owned by the domain teams. The data life cycle is also maintained by the domain teams. However, there is a need for data interoperability across domains. For example, if an organization has a finance domain team and a sales domain team, the finance domain team will need data from the sales domain team, and vice versa. Governance must be defined as to how the data is exchanged, the format of the data, what data can be exposed, network resiliency, security aspects, and so forth. Here, we need Federated Computational Governance to help.
Federated computational governance helps in standardizing the message exchange format across the products. It also helps in automated execution of decisions pertaining to security and access. There will be a set of rules, policies, and standards that has been decided upon by all the domain teams, and there will be automated enforcement of these rules, policies, and standards.
Now, let us use the data mesh principles we discussed and design a data mesh on Azure. We will take a use case of an enterprise consisting of finance, sales, human resources, procurement, and inventory departments. Let us build a data mesh that can expose data for each of these departments. The data generated by these departments are consumed across each of them. The item details in the inventory department are used in the sales department while generating an invoice when selling items to a prospective customer. Human resources payroll data and rewards and recognition data are used in the finance department to build the balance sheet for the department. The sales data from the sales department and the procurement data from the procurement department are used in the finance department when building the balance sheet for the company.
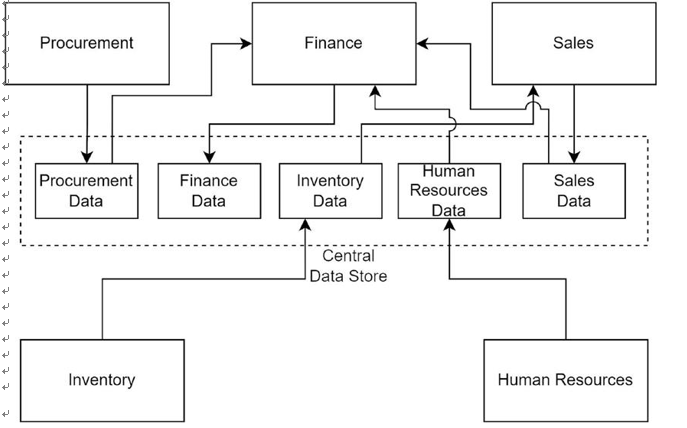
Figure 4-2. As-is data architecture
Figure 4-2 represents the as-is data architecture for the enterprise. The data are managed by a central data store. Each of the departments stores their data in the central data store. The finance department consumes data from human resources, sales, and procurement. Inventory data is consumed by the sales department. The central data team manages the data warehouse that stores and manages the central data. Each of these departments has a dependency on the central data team for data management, storage, and governance. The data engineers in the central data team are not experts for these domains. They do not understand how this data is produced or consumed. However, the engineers in the central data team are experts in storing and managing these data. The following are the steps to design a data mesh architecture on Azure:
Let us design data products for each of the domains.
Create Data Product for Human Resources Domain
We can start with the human resources domain product.
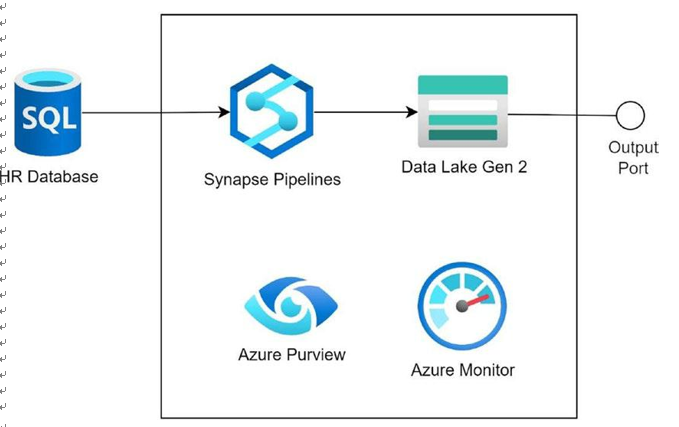
Figure 4-3. Human resources domain product
Figure 4-3 depicts the human resources domain product. The enterprise uses different human resources applications and portals that perform human resources tasks, like employee attendance, timecards, rewards and recognitions, performance management, and many more. All these human resources data are stored in the HR database built using Azure SQL. The Synapse pipeline reads the data from the HR database, transforms it into a consumable format, and then stores the data in the Synapse SQL pool. The Synapse pipeline can use the Copy activity to fetch the data from the HR database and put it in the Synapse SQL pool after processing the data. The Synapse SQL pool exposes the data to other domain products for consumption. Operational logs and metrics for Synapse are stored in Azure Monitor. Azure Monitor can be used to diagnose any run-time issues in the product. Azure Purview scans data capture and stores the data lineage, data schema, and other metadata information about the data that can help in discovering the data.
Create Data Product for Inventory Domain
Let us now design the inventory domain product.
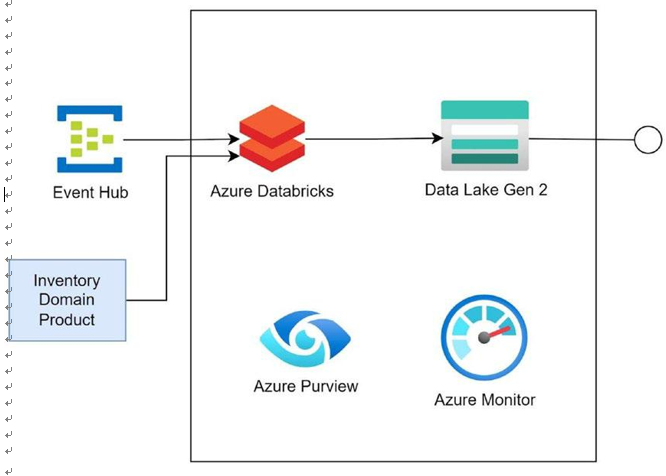
Figure 4-4. Inventory resources domain product
Figure 4-4 depicts the inventory domain product. The enterprise uses different inventory applications and portals that manage the inventory of the products that the enterprise develops. These applications add products’ stock and information data, distribution details, and other necessary metadata information. All these inventory data are stored in the inventory database built using Azure SQL. The Synapse pipeline reads the data from the inventory database, transforms it into a consumable format, and then stores the data in an Azure Data Lake Gen2. The Synapse pipeline can use the Copy activity to fetch the data from the HR database and put it in the Azure Data Lake Gen2 after processing it. Azure Data Lake Gen2 exposes the data to other domain products for consumption. Operational logs and metrics for Synapse are stored in Azure Monitor. Azure Monitor can be used to diagnose the run-time issues in the product. Azure Purview scans data capture and stores the data lineage, data schema, and other metadata information about the data that can help in discovering the data.
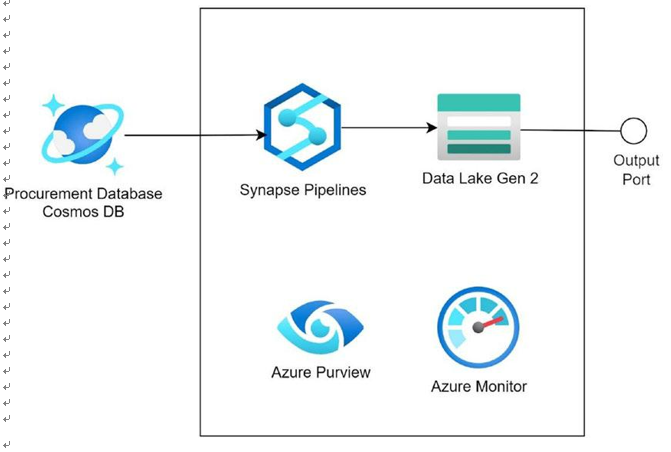
Figure 4-5 depicts the procurement domain product. There are different suppliers from whom the organization procures data. The data comprise procured product details, prices, and other necessary information. The data is directly ingested from the supplier system, and the data format varies from supplier to supplier. Cosmos DB database is used to store the supplier data. The Synapse pipeline reads the data from the supplier database, transforms the data into a consumable format, and then stores the data in
an Azure Data Lake Gen2. Synapse pipeline can use the Copy activity to fetch the data from HR database and put it in the Azure Data Lake Gen2 after processing the data.
Azure Data Lake Gen2 exposes the data to other domain products for consumption. Operational logs and metrics for Synapse are stored in Azure Monitor. Azure Monitor can be used to diagnose the run-time issues in the product. Azure Purview scans data capture and stores the data lineage, data schema, and other metadata information that can help in discovering the data.
Create Data Product for Sales Domain
Let us now design the sales domain product.
Figure 4-6. Sales domain product
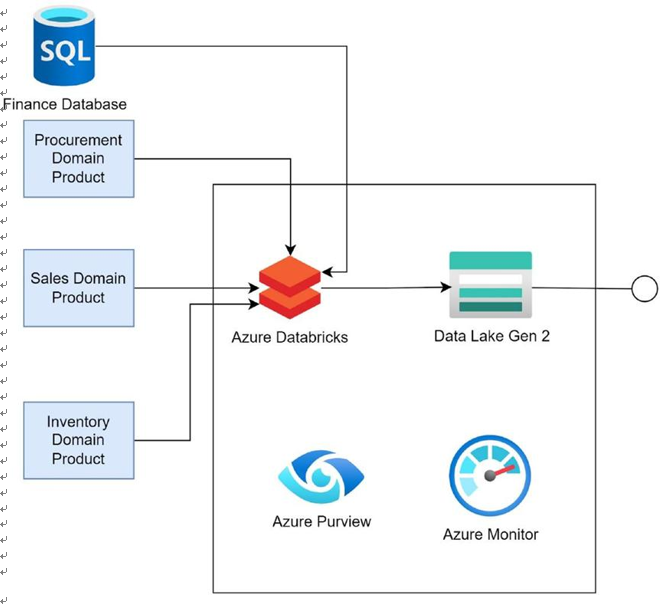
Figure 4-6 depicts the sales domain product. There are different sales channels for the enterprise. There are distributors that sell the products. There are also B2C sales for the products in the enterprise e-commerce portal. The sales data from multiple channels are ingested into Azure Databricks through Event Hub. The volume of data that is getting ingested is huge. So, the data are stored in Azure Databricks. Data from the inventory domain droduct are consumed by the sales domain product. Spark pipelines transform the data and put the data in an Azure Data Lake Gen2, which exposes the data to other domain products for consumption. Operational logs and metrics for Synapse are stored in Azure Monitor. Azure Monitor can be used to diagnose the run-time issues in the product. Azure Purview scans data capture and stores the data lineage, data schema, and other metadata information that can help in discovering the data.
Figure 4-7 depicts the finance domain product, which consumes data from the inventory, sales, and procurement domain products. The volume of data is huge. Azure Databricks is used to manage the huge amounts of data being ingested. Spark pipelines transform the data and put it in an Azure Data Lake Gen2, which exposes the data to other domain products for consumption. Operational logs and metrics for Synapse are stored in Azure Monitor. Azure Monitor can be used to diagnose the run-time issues in the product. Azure Purview scans data capture and stores the data lineage, data schema, and other metadata information that can help in discovering the data.
Create Self-Serve Data Platform
The self-serve data platform consists of the following components, which give data producers and consumers a self-service experience:
• Data mesh experience plane
• Data product experience plane
• Infrastructure plane
Figure 4-8 depicts the Azure services that can be used to build the self-serve data platform.
Figure 4-8. Self-serve platform components
Data Mesh Experience Plane
The data mesh experience plane helps customers to discover the data products, explore metadata, see relationships among the data, and so on. The data mesh plane is used by the data governance team to ensure data compliance and best practices by giving them a way to audit and explore the data. Azure Purview can scan the data products and pull the data information from the products, like metadata, data schemas, data lineage, etc.
Data Product Experience Plane
The data product experience plane helps the data producers to add, modify, and delete data in the domain products. Azure Functions can be used in data products to allow data producers to add, modify, or delete the data in the domain product. The Purview catalog in the domain product will expose the data schema definitions and metadata, allowing the data producers to work with the data in the data domain.
Infrastructure Plane
The infrastructure plane helps in self-provisioning of the data domain infrastructure. You can use Azure Resource Manager APIs exposed through Azure Functions to create and destroy infrastructure for the data domain products.
Federated Governance
Azure Policies can be used to bring in federated governance. Data landing zones can be created using Azure Policies that can control and govern API access and activities for the data producers and consumers. Azure Functions and Azure Resource Manager APIs can also be used for governance purposes. Azure Monitor alerts can be used for generating governance alerts and notifications.
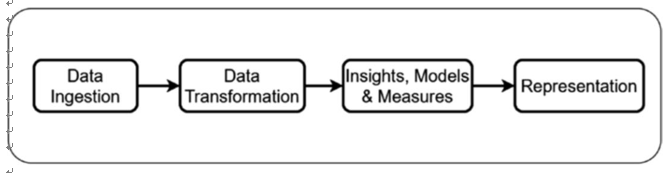
Data orchestration techniques are used to manage and coordinate the flow of data across various systems, applications, and processes within an organization. These techniques help ensure that data is collected, transformed, integrated, and delivered to the right place at the right time (Figure 5-1).
Figure 5-1. Some of the data engineering activities where orchestration is required
Data orchestration often involves data integration and extract, transform, load (ETL) processes. Data integration refers to combining data from different sources into a unified view, while ETL involves extracting data from source systems, transforming it to meet the target system’s requirements, and loading it into the destination system.
Orchestration has evolved alongside advancements in data management technologies and the increasing complexity of data ecosystems. Traditional approaches involved manual and ad-hoc methods of data integration, which were time-consuming and error-prone. As organizations started adopting distributed systems, cloud computing, and Big Data technologies, the need for automated and scalable data orchestration techniques became evident.
In the early days, batch processing was a common data orchestration technique. Data was collected over a period, stored in files or databases, and processed periodically. Batch processing is suitable for scenarios where real-time data processing is not necessary, and it is still used in various applications today.
With the rise of distributed systems and the need for real-time data processing, message-oriented middleware (MOM) became popular. MOM systems enable asynchronous communication between different components or applications by sending messages through a middleware layer. This technique decouples the sender and the receiver, allowing for more flexible and scalable data orchestration.
Enterprise Service Bus (ESB) is a software architecture that provides a centralized infrastructure for integrating various applications and services within an enterprise. It facilitates the exchange of data between different systems using standardized interfaces, protocols, and message formats. ESBs offer features like message routing, transformation, and monitoring, making them useful for data orchestration in complex environments.
Modern data orchestration techniques often involve the use of data pipelines and workflow orchestration tools both on cloud and on-premises for batch processing and real-time systems involving event-driven and continuous data streaming. The major areas that it covers are as follows:
• Data Pipelines and Workflow Orchestration: Modern data orchestration techniques often involve the use of data pipelines and workflow orchestration tools. Data pipelines provide a structured way to define and execute a series of data processing steps, including data ingestion, transformation, and delivery. Workflow orchestration tools help coordinate and manage the execution of complex workflows involving multiple tasks, dependencies, and error handling.
• Stream Processing and Event-Driven Architecture: As the demand for real-time data processing and analytics increased, stream processing and event-driven architecture gained prominence. Stream processing involves continuously processing and analyzing data streams in real-time, enabling organizations to derive insights and take immediate action. Event-driven architectures leverage events and event-driven messaging to trigger actions and propagate data changes across systems.
• Cloud-Based Data Orchestration: Cloud computing has greatly influenced data orchestration techniques. Cloud platforms offer various services and tools for data ingestion, storage, processing, and integration. They provide scalable infrastructure, on-demand resources, and managed services, making it easier to implement and scale data orchestration workflows.
Modern data orchestration encompasses a range of techniques and practices that enable organizations to manage and integrate data effectively in today’s complex data ecosystems.
They go through cycles of data ingestion, data transformation, defining models and measures, and finally serving the data via different modes and tools based on latency, visibility, and accessibility requirements for representation (Figure 5-2).
Figure 5-2. Typical data orchestration flow in data analytics and engineering
Here are key aspects to understand about modern data orchestration:
• Data Integration and ETL: Data integration remains a fundamental component of data orchestration. It involves combining data from disparate sources, such as databases, cloud services, and third-party APIs, into a unified and consistent format. Extract, transform, load (ETL) processes are commonly employed to extract data from source systems, apply transformations or cleansing, and load it into target systems.
• Data Pipelines: Data pipelines provide a structured and automated way to process and move data from source to destination. A data pipeline typically consists of a series of interconnected steps that perform data transformations, enrichment, and validation. Modern data pipeline solutions often leverage technologies like Apache Kafka, Apache Airflow, or cloud-based services such as AWS Glue, Google Cloud Dataflow, or Azure Data Factory.
• Event-Driven Architectures: Event-driven architectures have gained popularity in data orchestration. Instead of relying solely on batch processing, event-driven architectures enable real-time data processing by reacting to events or changes in the data ecosystem. Events, such as data updates or system notifications, trigger actions and workflows, allowing for immediate data processing, analytics, and decision-making.
• Stream Processing: Stream processing focuses on analyzing and processing continuous streams of data in real-time. It involves handling data in motion, enabling organizations to extract insights, perform real-time analytics, and trigger actions based on the data flow. Technologies like Apache Kafka, Apache Flink, and Apache Spark Streaming are commonly used for stream processing.
• Data Governance and Metadata Management: Modern data orchestration also emphasizes data governance and metadata management. Data governance ensures that data is properly managed, protected, and compliant with regulations. Metadata management involves capturing and organizing metadata, which provides valuable context and lineage information about the data, facilitating data discovery, understanding, and lineage tracking.
• Cloud-Based Data Orchestration: Cloud computing platforms offer robust infrastructure and services for data orchestration. Organizations can leverage cloud-based solutions to store data, process it at scale, and access various data-related services, such as data lakes, data warehouses, serverless computing, and managed ETL/ELT services. Cloud platforms also provide scalability, flexibility, and cost-efficiency for data orchestration workflows.
• Automation and Workflow Orchestration: Automation plays a vital role in modern data orchestration. Workflow orchestration tools, such as Apache Airflow, Luigi, or commercial offerings like AWS Step Functions or Azure Logic Apps, allow organizations to define, schedule, and execute complex data workflows. These tools enable task dependencies, error handling, retries, and monitoring, providing end-to-end control and visibility over data processing pipelines.
• Data Quality and DataOps: Data quality is a critical aspect of modern data orchestration. Organizations focus on ensuring data accuracy, consistency, completeness, and timeliness throughout the data lifecycle. DataOps practices, which combine data engineering, DevOps, and Agile methodologies, aim to streamline and automate data-related processes, improve collaboration between teams, and enhance data quality.
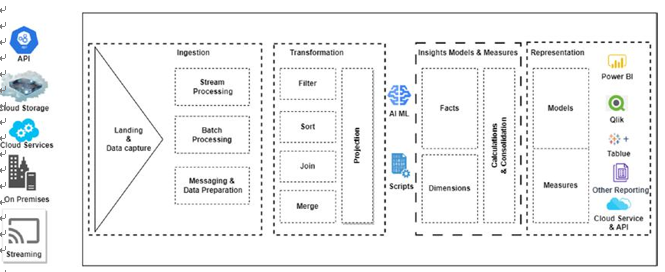
Figure 5-3. A generic, well-orchestrated data engineering and analytics activity
A well-orchestrated data engineering model for modern data engineering involves key components and processes (Figure 5-3). It begins with data ingestion, where data from various sources, such as databases, APIs, streaming platforms, or external files, is collected and transformed using ETL processes to ensure quality and consistency. The ingested data is then stored in suitable systems, like relational databases, data lakes, or distributed file systems. Next, data processing takes place, where the ingested data is transformed, cleansed, and enriched using frameworks like Apache Spark or SQL-based transformations. They are further segregated into models and measures, sometimes using OLAP or tabular fact and dimensions to be further served to analytic platforms such as power BI for business-critical reporting.
Data orchestration is crucial for managing and scheduling workflows, thus ensuring seamless data flow. Data quality and governance processes are implemented to validate, handle anomalies, and maintain compliance with regulations. Data integration techniques bring together data from different sources for a unified view, while data security measures protect sensitive information. Finally, the processed data is delivered to end users or downstream applications through various means, such as data pipelines, reports, APIs, or interactive dashboards. Flexibility, scalability, and automation are essential considerations in designing an effective data engineering model.
One of the key aspects to grasp in data orchestration is the cyclical nature of activities that occur across data layers. These cycles of activity play a crucial role in determining the data processing layers involved in the storage and processing of data, whether it is stored permanently or temporarily.
Data processing layers and their transformation in the ETL (extract, transform, load) orchestration process play a crucial role in data management and analysis. These layers, such as work area staging, main, OLAP (online analytical processing), landing, bronze, gold, silver, and zones, enable efficient data processing, organization, and optimization.
The evolution of data processing layers has had a significant impact on data orchestration pipelines and the ETL (extract, transform, load) process. Over time, these layers have become more sophisticated and specialized, enabling improved data processing, scalability, and flexibility.
In traditional ETL processes, the primary layers consisted of extraction, transformation, and loading, forming a linear and sequential flow. Data was extracted from source systems, transformed to meet specific requirements, and loaded into a target system or data warehouse.
However, these traditional layers had limited flexibility and scalability. To address these shortcomings, the data staging layer was introduced. This dedicated space allowed for temporary data storage and preparation, enabling data validation, cleansing, and transformation before moving to the next processing stage.
The staging layer’s enhanced data quality provided better error handling and recovery and paved the way for more advanced data processing. As data complexity grew, the need for a dedicated data processing and integration layer emerged. This layer focused on tasks like data transformation, enrichment, aggregation, and integration from multiple sources. It incorporated business rules, complex calculations, and data quality checks, enabling more sophisticated data manipulation and preparation.
With the rise of data warehousing and OLAP technologies, the data processing layers evolved further. The data warehousing and OLAP layer supported multidimensional analysis and faster querying, utilizing optimized structures for analytical processing. These layers facilitated complex reporting and ad-hoc analysis, empowering organizations with valuable insights.
The advent of big data and data lakes introduced a new layer specifically designed for storing and processing massive volumes of structured and unstructured data. Data lakes served as repositories for raw and unprocessed data, facilitating iterative and exploratory data processing. This layer enabled data discovery, experimentation, and analytics on diverse datasets, opening doors to new possibilities.
In modern data processing architectures, multiple refinement stages are often included, such as landing, bronze, silver, and gold layers. Each refinement layer represents a different level of data processing, refinement, and aggregation, adding value to the data and providing varying levels of granularity for different user needs. These refinement layers enable efficient data organization, data governance, and improved performance in downstream analysis, ultimately empowering organizations to extract valuable insights from their data.
The modern data processing architecture has made data orchestration efficient and effective with better speed, security, and governance. Here is the brief on the key impacts of modern data processing architecture on data orchestration and ETL:
• Scalability: The evolution of data processing layers has enhanced the scalability of data orchestration pipelines. The modular structure and specialized layers allow for distributed processing, parallelism, and the ability to handle large volumes of data efficiently.
• Flexibility: Advanced data processing layers provide flexibility in handling diverse data sources, formats, and requirements. The modular design allows for the addition, modification, or removal of specific layers as per changing business needs. This flexibility enables organizations to adapt their ETL pipelines to evolving data landscapes.
• Performance Optimization: With specialized layers, data orchestration pipelines can optimize performance at each stage. The separation of data transformation, integration, aggregation, and refinement allows for parallel execution, selective processing, and efficient resource utilization. It leads to improved data processing speed and reduced time to insight.
• Data Quality and Governance: The inclusion of data staging layers and refinement layers enhances data quality, consistency, and governance. Staging areas allow for data validation and cleansing, reducing the risk of erroneous or incomplete data entering downstream processes. Refinement layers ensure data accuracy, integrity, and adherence to business rules.
• Advanced Analytics: The availability of data warehousing, OLAP, and Big Data layers enables more advanced analytics capabilities. These layers support complex analytical queries, multidimensional analysis, and integration with machine learning and AI algorithms. They facilitate data-driven decision-making and insight generation.
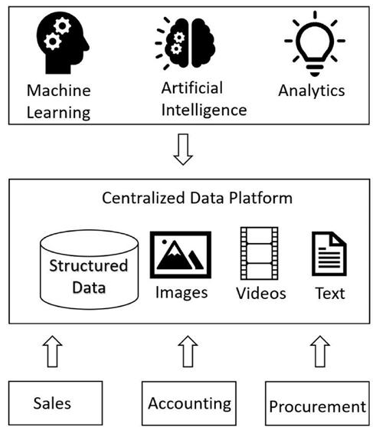
Modern organizations keep data in centralized data platforms. Data get generated by multiple sources and are ingested into this data platform. This centralized data platform serves data for analytics and other data consumption needs for the data consumers in the organization. There are multiple departments in an organization, like sales, accounting, procurement, and many more, that can be visualized as domains. Each of these domains ingests data from this centralized data platform. There are data engineers, data administrators, data analysts, and other such roles that work from the centralized data platform. These data professionals work in silos and have very little knowledge of how these data relate to the domain functionality where they were generated. Managing the huge amount of data is cumbersome, and scaling the data for consumption is a big challenge. Making this data reusable and consumable for analytics and machine learning purposes is a big challenge. Storing, managing, processing, and serving the data centrally is monolithic in nature. Figure 4-1 represents the modern data problem. The data is kept in a monolithic centralized data platform that has limited scaling capability, and data is kept and handled in silos.
Figure 4-1. Modern data problem
The data mesh solves this modern data problem. It is a well-defined architecture or pattern that gives data ownership to the domains or the departments that are generating the data. The domains will generate, store, and manage the data and expose the data to the consumers as a product. This approach makes the data more scalable and discoverable as the data are managed by the domains, and these domains understand the data very well and know what can be done with them. The domains can enforce strict security and compliance mechanisms to secure the data. By adopting a data mesh, we are moving away from the monolithic centralized data platform to a decentralized and distributed data platform where the data are exposed as products and the ownership lies with the domains. Data are organized and exposed by the specific domain that owns the data generation.
The amount of data orchestration required also depends on the needs of the data processing layers, and it’s important to briefly understand each layer and its role in the orchestration and underlying ETL processes.
Here’s a breakdown of the importance of each data layer and its role in the ETL flows and process:
• Work area staging: The staging area is used to temporarily store data before it undergoes further processing. It allows for data validation, cleansing, and transformation activities, ensuring data quality and integrity. This layer is essential for preparing data for subsequent stages.
• Main layer: The main layer typically serves as the central processing hub where data transformations and aggregations take place. It may involve joining multiple data sources, applying complex business rules, and performing calculations. The main layer is responsible for preparing the data for analytical processing.
• Landing, bronze, gold, and silver layers: These layers represent different stages of data refinement and organization in a data lake or data warehouse environment. The landing layer receives raw, unprocessed data from various sources. The bronze layer involves the initial cleansing and transformation of data, ensuring its accuracy and consistency. The gold layer further refines the data, applying additional business logic and calculations. The silver layer represents highly processed and aggregated data, ready for consumption by end users or downstream systems. Each layer adds value and structure to the data as it progresses through the ETL pipeline.
• OLAP layer: OLAP is designed for efficient data retrieval and analysis. It organizes data in a multidimensional format, enabling fast querying and slicing-and-dicing capabilities. The OLAP layer optimizes data structures and indexes to facilitate interactive and ad- hoc analysis.
Data Movement Optimization: OneLake Data and Its Impact on Modern Data Orchestration One of the heavyweight tasks in data orchestration is around data movement through data pipelines. With the optimization of zones and layers on cloud data platforms, the new data architecture guidance emphasizes minimizing data movement across the platform. The goal is to reduce unnecessary data transfers and duplication, thus optimizing costs and improving overall data processing efficiency.
This approach helps optimize costs by reducing network bandwidth consumption and data transfer fees associated with moving large volumes of data. It also minimizes the risk of data loss, corruption, or inconsistencies that can occur during the transfer process.
Additionally, by keeping data in its original location or minimizing unnecessary duplication, organizations can simplify data management processes. This includes tracking data lineage, maintaining data governance, and ensuring compliance with data protection regulations.