Create an AWS Glue Job to Convert the Raw Data into a Delta Table
Go to AWS Glue and click on Go to workflows as shown in Figure 3-60. We will get navigated to the AWS Glue studio, where we can create the AWS Glue job to convert the raw CSV file into a delta table.

Figure 3-60. Go to workflows
Click on Jobs as in Figure 3-61. We need to create the workflow for the job and execute it to convert the raw CSV file into a delta table.
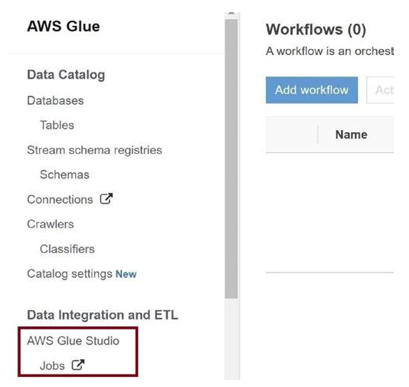
Figure 3-61. Click on Jobs
We will be using the delta lake connector in the AWS Glue job. We need to activate it.
Go to the Marketplace, as in Figure 3-62.
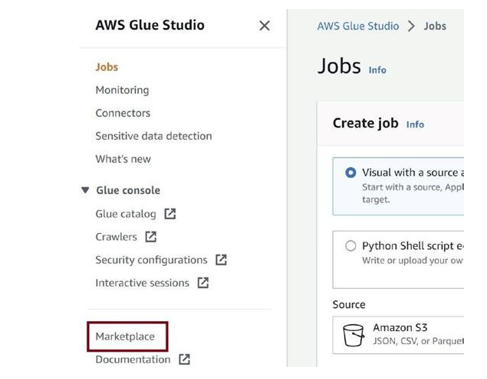
Figure 3-62. Click on Marketplace
Search for delta lake as in Figure 3-63, and then click on Delta Lake Connector for AWS Glue.
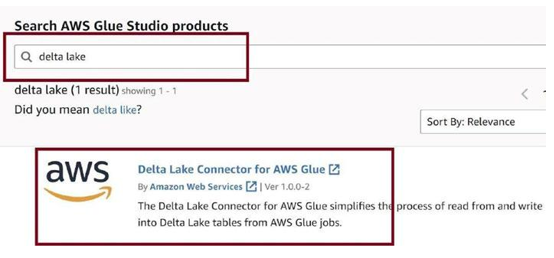
Figure 3-63. Activate delta lake connector
Click on Continue to Subscribe as in Figure 3-64.

Figure 3-64. Continue to Subscribe
Click on Continue to Configuration as in Figure 3-65.
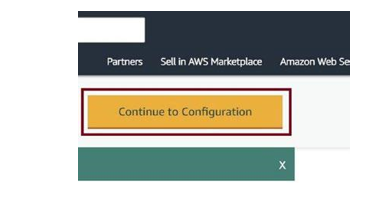
Figure 3-65. Continue to Configuration
Click on Continue to Launch as in Figure 3-66.

Figure 3-66. Continue to Launch
Click on Usage instructions as in Figure 3-67. The usage instructions will open up. We have some steps to perform on that page.
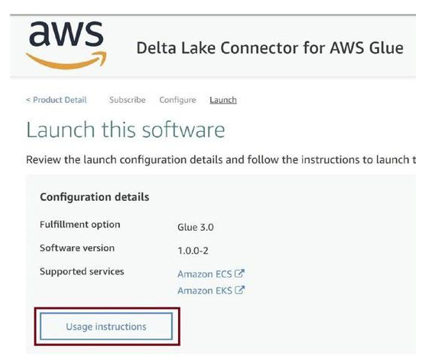
Figure 3-67. Click Usage Instructions
Read the usage instructions once and then click on Activate the Glue connector from AWS Glue Studio, as in Figure 3-68.
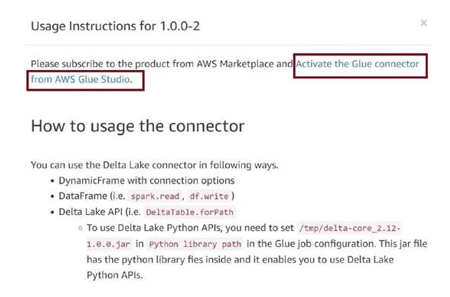
Figure 3-68. Activate Glue connector
Provide a name for the connection, as in Figure 3-69, and then click on Create a connection and activate connector.
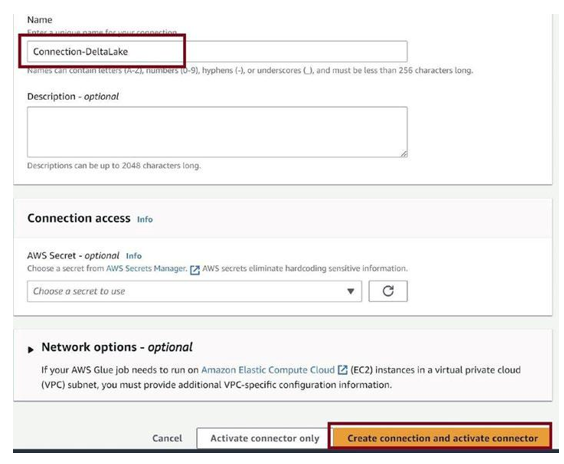
Figure 3-69. Create connection and activate connector
Once the connector gets activated, go back to the AWS Glue studio and click on Jobs, as in Figure 3-70.

Figure 3-70. Click on Jobs
Select option Visual with a source and target and depict the source as Amazon S3, as in Figure 3-71.
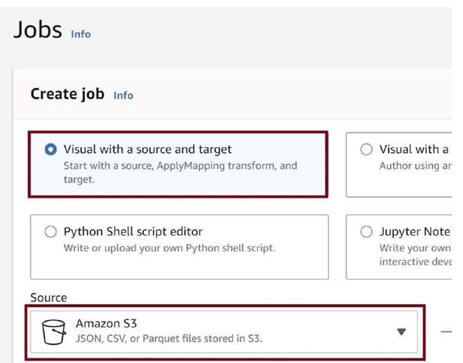
Figure 3-71. Configure source
Select the target as Delta Lake Connector 1.0.0 for AWS Glue 3.0, as in Figure 3-72. We activated the connector in the marketplace and created a connection earlier. Click on Create.
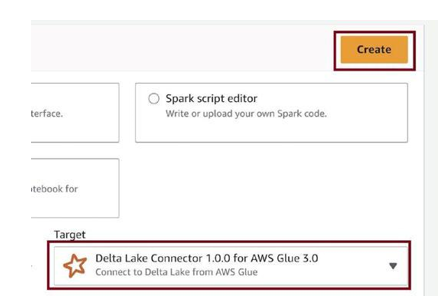
Figure 3-72. Configure target
Go to the S3 bucket and copy the S3 URI for the raw-data folder, as in Figure 3-73.
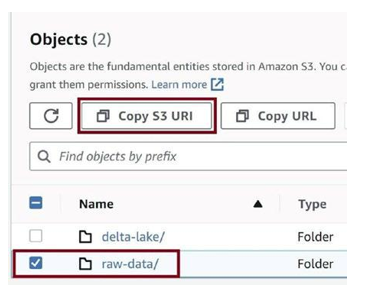
Figure 3-73. Copy URI
Provide the S3 URI you copied and configure the data source, as in Figure 3-74. Make sure you mark the data format as CSV and check Recursive.

Figure 3-74. Source settings
Scroll down and check the First line of the source file contains column headers option, as in Figure 3-75.

Figure 3-75. Source settings
Click on ApplyMapping as in Figure 3-76 and provide the data mappings and correct data types. The target parquet file will be generated with these data types.
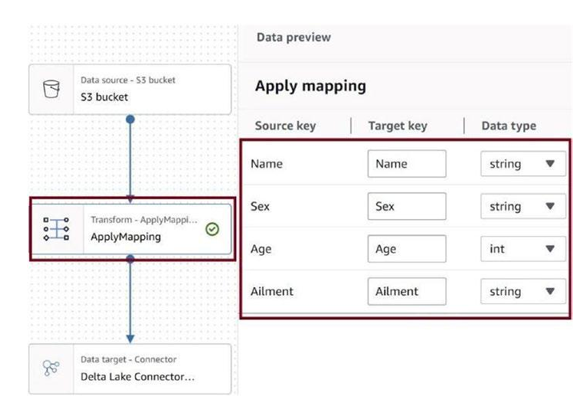
Figure 3-76. Configure mappings
Click on Delta Lake Connector, and then click on Add new option, as in Figure 3-77.
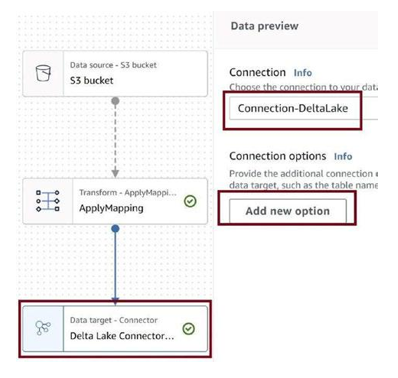
Figure 3-77. Add new option
Provide Key as path and Value as URI for the delta-lake folder in the S3 bucket, as in Figure 3-78.
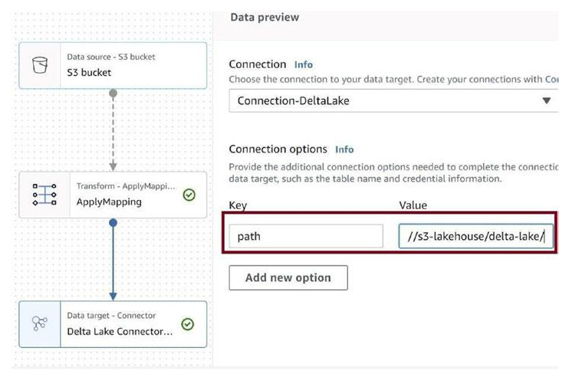
Figure 3-78. Configure target
Go to the Job details as in Figure 3-79 and set IAM Role as the role we created as a prerequisite with all necessary permissions.
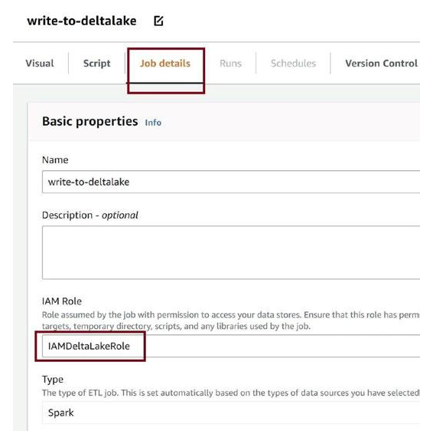
Figure 3-79. Provide IAM role
Click on Save as in Figure 3-80 and then run the job.

Figure 3-80. Save and run
Once the job runs successfully, go to the delta-lake folder in the S3 bucket. You can see the delta table parquet file generated in Figure 3-81.
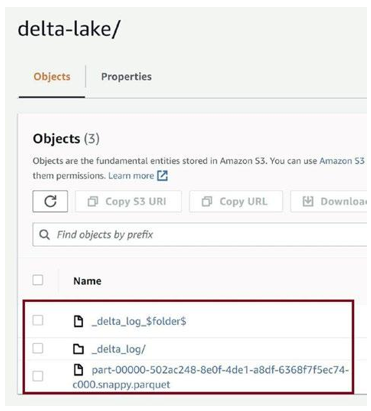
Figure 3-81. Generated delta table in the delta-lake folder

