Modern Data Orchestration in Detail
Modern data orchestration encompasses a range of techniques and practices that enable organizations to manage and integrate data effectively in today’s complex data ecosystems.
They go through cycles of data ingestion, data transformation, defining models and measures, and finally serving the data via different modes and tools based on latency, visibility, and accessibility requirements for representation (Figure 5-2).
Figure 5-2. Typical data orchestration flow in data analytics and engineering
Here are key aspects to understand about modern data orchestration:
• Data Integration and ETL: Data integration remains a fundamental component of data orchestration. It involves combining data from disparate sources, such as databases, cloud services, and third-party APIs, into a unified and consistent format. Extract, transform, load (ETL) processes are commonly employed to extract data from source systems, apply transformations or cleansing, and load it into target systems.
• Data Pipelines: Data pipelines provide a structured and automated way to process and move data from source to destination. A data pipeline typically consists of a series of interconnected steps that perform data transformations, enrichment, and validation. Modern data pipeline solutions often leverage technologies like Apache Kafka, Apache Airflow, or cloud-based services such as AWS Glue, Google Cloud Dataflow, or Azure Data Factory.
• Event-Driven Architectures: Event-driven architectures have gained popularity in data orchestration. Instead of relying solely on batch processing, event-driven architectures enable real-time data processing by reacting to events or changes in the data ecosystem. Events, such as data updates or system notifications, trigger actions and workflows, allowing for immediate data processing, analytics, and decision-making.
• Stream Processing: Stream processing focuses on analyzing and processing continuous streams of data in real-time. It involves handling data in motion, enabling organizations to extract insights, perform real-time analytics, and trigger actions based on the data flow. Technologies like Apache Kafka, Apache Flink, and Apache Spark Streaming are commonly used for stream processing.
• Data Governance and Metadata Management: Modern data orchestration also emphasizes data governance and metadata management. Data governance ensures that data is properly managed, protected, and compliant with regulations. Metadata management involves capturing and organizing metadata, which provides valuable context and lineage information about the data, facilitating data discovery, understanding, and lineage tracking.
• Cloud-Based Data Orchestration: Cloud computing platforms offer robust infrastructure and services for data orchestration. Organizations can leverage cloud-based solutions to store data, process it at scale, and access various data-related services, such as data lakes, data warehouses, serverless computing, and managed ETL/ELT services. Cloud platforms also provide scalability, flexibility, and cost-efficiency for data orchestration workflows.
• Automation and Workflow Orchestration: Automation plays a vital role in modern data orchestration. Workflow orchestration tools, such as Apache Airflow, Luigi, or commercial offerings like AWS Step Functions or Azure Logic Apps, allow organizations to define, schedule, and execute complex data workflows. These tools enable task dependencies, error handling, retries, and monitoring, providing end-to-end control and visibility over data processing pipelines.
• Data Quality and DataOps: Data quality is a critical aspect of modern data orchestration. Organizations focus on ensuring data accuracy, consistency, completeness, and timeliness throughout the data lifecycle. DataOps practices, which combine data engineering, DevOps, and Agile methodologies, aim to streamline and automate data-related processes, improve collaboration between teams, and enhance data quality.
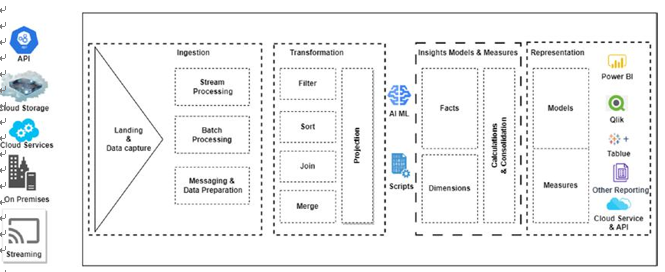
Figure 5-3. A generic, well-orchestrated data engineering and analytics activity
A well-orchestrated data engineering model for modern data engineering involves key components and processes (Figure 5-3). It begins with data ingestion, where data from various sources, such as databases, APIs, streaming platforms, or external files, is collected and transformed using ETL processes to ensure quality and consistency. The ingested data is then stored in suitable systems, like relational databases, data lakes, or distributed file systems. Next, data processing takes place, where the ingested data is transformed, cleansed, and enriched using frameworks like Apache Spark or SQL-based transformations. They are further segregated into models and measures, sometimes using OLAP or tabular fact and dimensions to be further served to analytic platforms such as power BI for business-critical reporting.
Data orchestration is crucial for managing and scheduling workflows, thus ensuring seamless data flow. Data quality and governance processes are implemented to validate, handle anomalies, and maintain compliance with regulations. Data integration techniques bring together data from different sources for a unified view, while data security measures protect sensitive information. Finally, the processed data is delivered to end users or downstream applications through various means, such as data pipelines, reports, APIs, or interactive dashboards. Flexibility, scalability, and automation are essential considerations in designing an effective data engineering model.
One of the key aspects to grasp in data orchestration is the cyclical nature of activities that occur across data layers. These cycles of activity play a crucial role in determining the data processing layers involved in the storage and processing of data, whether it is stored permanently or temporarily.
Data processing layers and their transformation in the ETL (extract, transform, load) orchestration process play a crucial role in data management and analysis. These layers, such as work area staging, main, OLAP (online analytical processing), landing, bronze, gold, silver, and zones, enable efficient data processing, organization, and optimization.
The evolution of data processing layers has had a significant impact on data orchestration pipelines and the ETL (extract, transform, load) process. Over time, these layers have become more sophisticated and specialized, enabling improved data processing, scalability, and flexibility.

